SigmaQ
Corporate Default Risk Technology

Bayesian Thinking
in Credit Risk
I am Egemen Erdogdu and I work as a Data Scientist at the intersection of Data Engineering and Quant DevOps at SigmaQ Analytics. As a data scientist, I am often asked in client meetings how SigmaQ’s model for corporate default risk works. In this short post, I will try to explain the cornerstones of the model from a slightly more technical point of view and not focus so much on its economic understanding (see https://sigmaqanalytics.com/insights/ for plenty of material on its economic underpinnings).
SigmaQ’s AI-inspired model makes heavy use of Bayesian inference methods, like so many models in the field of AI. But why do AI models use Bayesian methods so often? One of the main reasons is that it offers a framework where learning evolves with the accumulation of evidence. This helps in making better predictions and decisions based on data.
Although conceptually simple, Bayesian methods can be mathematically and numerically very challenging, especially when simulation-based Monte Carlo methods need to be applied, e.g. in the context of complex models that cannot be processed in closed form. These obstacles have been overcome in the last decade with the advent of modern data science methods and ever-increasing computing power, making Bayesian inference methods more accessible.
Fundamentals
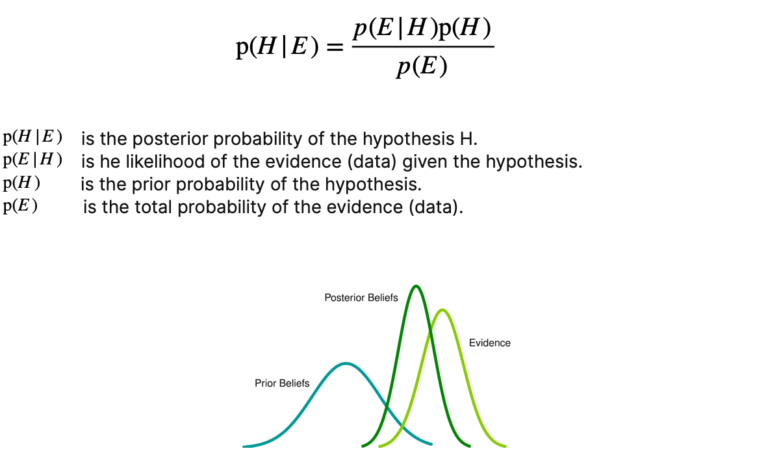
At the core of Bayesian statistics is the idea that prior beliefs should be updated as new data is acquired. The integration of prior knowledge with new data leads to a continuously improving model.
The initial belief about a hypothesis is encoded in the prior (distribution). It is combined with the likelihood of the new data to determine the posterior (distribution), which encodes our improved belief.
The mathematical concept underlying this idea is the famous Bayes’ theorem:
Tools and Methods
Bayesian methods are not just theoretical constructs. They are practical tools that let models learn from data. A key technique that bridges statistical theory with computational practice is probabilistic programming. It simplifies the application of Bayesian methods and enables data scientists to define probabilistic models that incorporate prior knowledge and uncertainty.
Probabilistic Programming allows for automatic Bayesian inference on user-defined probabilistic models. Recent advances in Markov chain Monte Carlo (MCMC) sampling allow inference on increasingly complex models.
Two popular probabilistic programming packages are PyMC and Stan.
PyMC is an open source Probabilistic Programming framework written in Python that uses Theano to compute gradients via automatic differentiation as well as compile probabilistic programs on-the-fly to C for increased speed. Contrary to other Probabilistic Programming languages, PyMC allows model specification directly in Python code.
Stan is a probabilistic programming language implemented in C++ and available through various interfaces (RStan, PyStan, CmdStan, etc.). Stan excels in efficiently performing HMC (Hamilton Monte Carlo) and NUTS (No-U-Turn-Sampler) sampling and is known for its speed and accuracy. It also includes extensive diagnostics and tools for model checking.
TensorFlow Probability (TFP) is a library for probabilistic reasoning and statistical analysis in TensorFlow. TFP provides a range of distributions, bijectors, and MCMC algorithms. Its integration with TensorFlow ensures efficient execution on diverse hardware. It allows users to seamlessly combine probabilistic models with deep learning architectures.
Applications
Bayesian methods are applied across various domains. They are not only theoretical but also intensely practical, reshaping industries by providing deeper insights and better predictions. Extensive use of them is made for example in industries like:
‣ Healthcare diagnostics
‣ Chemical engineering
‣ Autonomous systems and robotics
‣ Finance sector
Let’s look at an example. We will see how to implement a simple logistic regression using the probabilistic programming package PyMC.
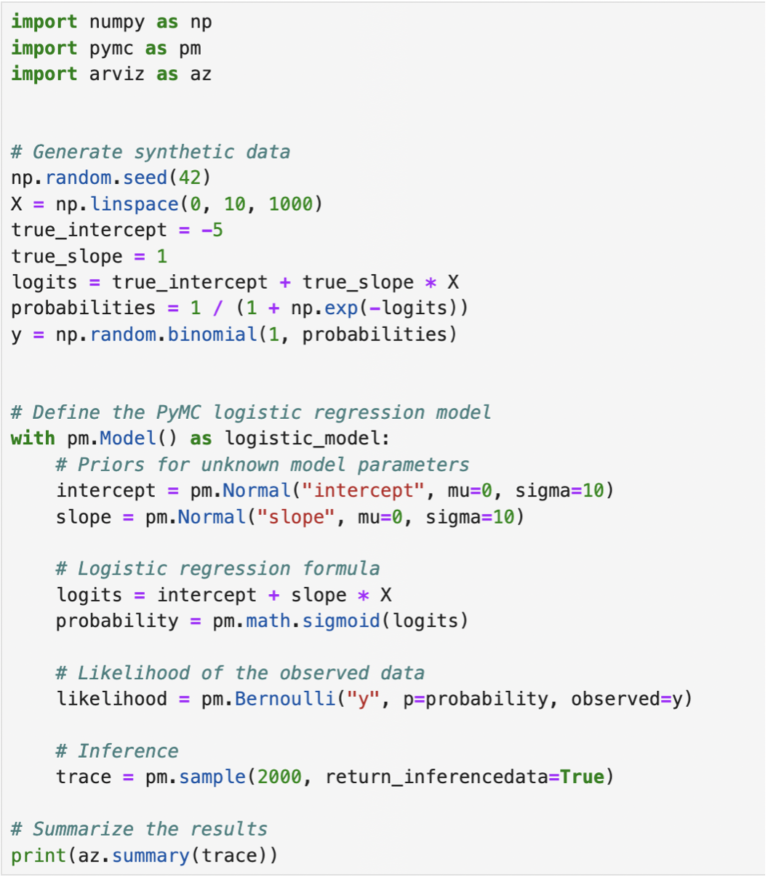
Let’s understand the code above step-by-step.
‣ It sets initial beliefs (priors) for the intercept, slope and noise.
‣ It defines a likelihood function based on these priors and the observed data.
‣ The code uses Markov Chain Monte Carlo (MCMC) sampling to generate samples from the posterior distribution.
‣ Finanlly, it summarizes the results to show estimated parameter values and uncertainties.
Wrapping up
Bayesian methods integrate prior beliefs with new data for better and more accurate decision-making. They are not only theoretical but also intensely practical, reshaping industries by providing deeper insights and better predictions. A key technique that bridges statistical theory with computational practice is probabilistic programming, which is implemented in tools like PyMC, Stan, and TensorFlow Probability. These tools enable data scientists to encode models with rich probabilistic semantics, simplifying the complex process of Bayesian inference.
SigmaQ’s Default Risk Technology
We use Bayesian ML to deliver best in-class credit risk data. Our approach allows you to take advantage of modern modelling techniques while maintaining full explainability.
Using this approach, we create default predictions based on company’s balance sheet data and share price history. Full transparency is guaranteed, no non-observable data is used, no model overlays or subjective information is added.
The model was calibrated on a time horizon from 2008-2023 with the time period from 1970-2008 as a Bayesian prior, thus covering overall more than 50-years of history. The financial crisis from 2008/09 is fully included.
SigmaQ PD are based on over 2 million observations and more than 3’000 corporate defaults. They are available for more than 35’000 companies, covering 70+ markets worldwide.
Please visit our website www.sigmaqanalytics.com for more details or contact us at contact@sigmaqanalytics.com.